
If you’ve read anything on animal testing, you’ll have read something to the effect that 'more than 90% of drugs tested in animals fail in humans'. Is that some damning indictment of animal models? Absolutely not. Let’s unpack this a bit.
The 90% statistic refers to regulatory safety testing. Other sorts of animal use, like discovering decapod sentience through ‘curiosity-driven’ basic research, will be discussed in another article since the applications are so broad and the application of the research so complex that percentages are usually meaningless.
How drugs get licensed
In drug trials, all drugs intended for humans are tested on humans through three stages of clinical trial before being licensed for public use. Phase 1 of human testing looks primarily at safety, whereas phases 2 and 3 are for safety and then efficacy. Each stage uses more human volunteers than the last and the later stages might include those with a particular medical condition. There is also a post-licensing stage 4, where new treatments are introduced to the wider population, for instance in the clinic by doctors.
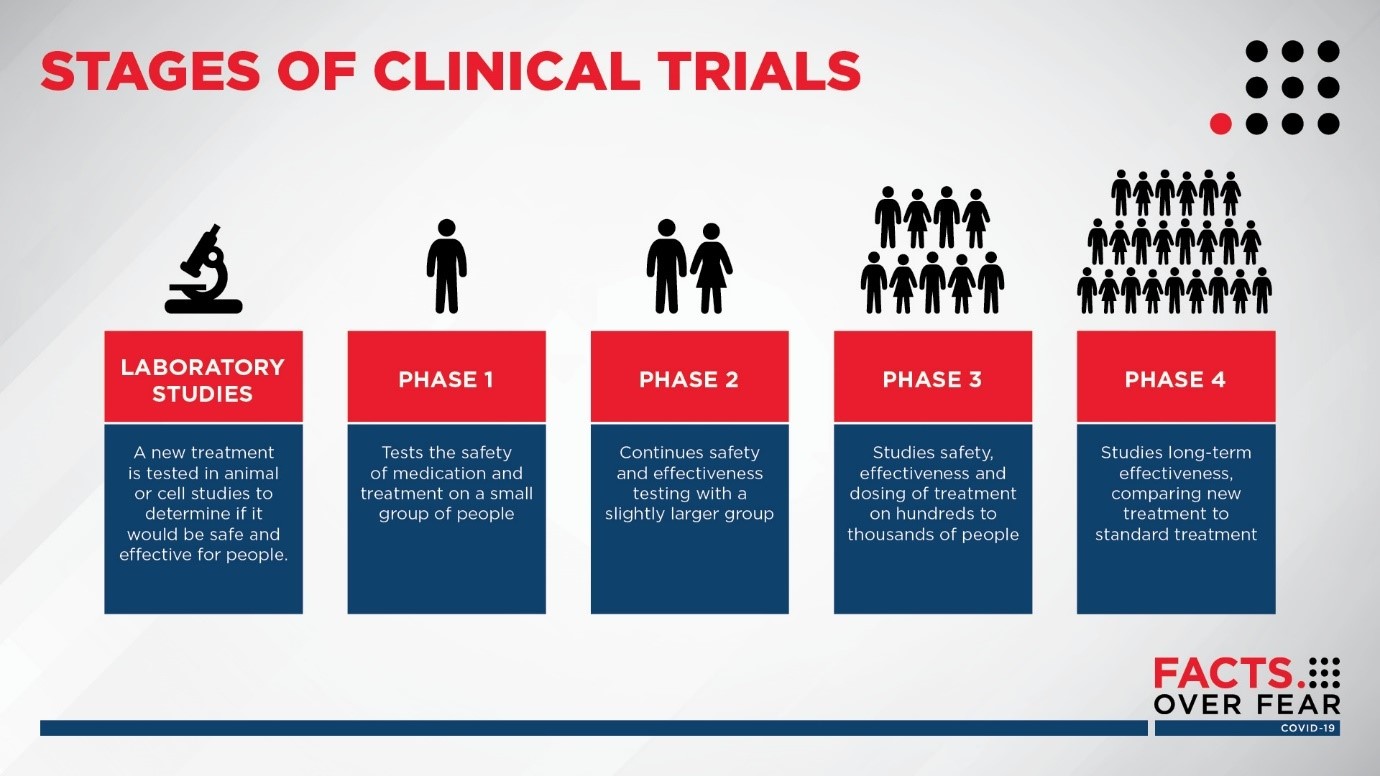
Image: Sanford Health
Adverse reactions noted after a drug is licensed are fed back to the medicine’s regulator, the Medicines and Healthcare Devices Regulatory Authority (MHRA), which might do things like update the safety information in the booklet that comes with the medicines. Lots of medicines have their safety advice updated as the medicine is used in a greater number of patients.
This is because drugs are licensed on the grounds of what they do in general, e.g. shrink a tumour or lower blood sugar. However, to what extent they work in an individual will vary greatly depending on dozens of factors from genetics to weight to hormones – even to the time of day. This is why there are specialist doctors for different diseases, as well as GPs, who take a patient-centric perspective on the medical tools available for that person (or animal). Hence, very few medicines are withdrawn – it’s usually a case of finessing the practice and guidance on using them safely and optimally and adapting their use for specific patients.
Preclinical testing
Before drugs can go to human trials, they must pass a standard battery of safety tests using both animal and non-animal methods. These tests tend to be specified by bodies like the OECD (mainly for chemicals) and the International Conference on Harmonisation (mainly for pharmaceuticals), which can pool knowledge about how to use the best methods of safety testing, whatever these may be.
Non-animal methods of drug testing can perform well but tend to be limited in scope to one organ system or one effect, whereas animal models tend to give a broader picture of how drugs will act in a whole living body and across a dozen organs at once.
For some applications, non-animal methods are enough to conclude that drug development shouldn’t proceed, and the compound is therefore eliminated before hitting either the human or animal testing stages.
With those drugs that proceed, animals are very good at ‘predicting’ if a drug will be ‘safe’ in the first human trials.
There are different statistical tools that can be used to determine this safety. Bayesian modelling (figure 1 below) can find ‘true positives’ (PPVs) and ‘true negatives’ (NPV) i.e. a percentage certainty that something will be safe in stage 1 human trials. Likelihood ratios (figure 2) offer a probability of safety.
|
Bayesian modelling, NPV safety prediction |
||
|
Organ category |
Dog to human |
Mouse to human |
|
Pulmonary |
96% |
95% |
|
Biochemical |
95% |
93% |
|
Renal |
95% |
96% |
|
Ophthalmology |
94% |
96% |
|
Haematology |
93% |
92% |
|
Cutaneous |
91% |
82% |
|
Musculoskeletal |
91% |
92% |
|
Cardiovascular |
91% |
75% |
|
Nervous system |
90% |
93% |
|
Liver |
88% |
89% |
|
Gastrointestinal |
76% |
69% |
Figure 1: IQ Consortium translational database
|
Likelihood ratios |
|||
|
Pre-test probability |
Pre-test odds |
Post-test odds |
Post-test probability |
|
10% |
0.11 |
3.16 |
76% |
|
20% |
0.25 |
7.11 |
88% |
|
30% |
0.43 |
12.18 |
92% |
|
40% |
0.67 |
18.95 |
95% |
|
50% |
1.00 |
28.43 |
97% |
|
60% |
1.50 |
42.65 |
98% |
|
70% |
2.33 |
66.34 |
99% |
|
80% |
4.00 |
113.72 |
99% |
|
90% |
9.00 |
255.87 |
100% |
Figure 2: Data from https://pubmed.ncbi.nlm.nih.gov/24329742/
Different species of animal do more or less well at translating to humans depending on the target organs, the type of thing being tested and the size of its molecules. These species differences are well-known, as is the fact that you can increase your certainty that something will be safe or not if a rodent and a non-rodent species both yield similar results.
Thus, the normal testing regime uses species like rats, plus a non-rodent species, usually a dog or primate. Around three-quarters of tests involve suffering in the mildest category, such as a blood test, with a quarter in the moderate category and very few in severe. This is because most of the information about the possible dangers of a new drug comes from a post-mortem of the animal that reveals changes to the internal organs and tissues, rather than observing whether a live animal gets sick or not.
The fact that animals are good predictors of safety in humans is important because 40% of potential new drugs are ultimately removed due to failing these pre-human tests. This means that 40% of possible new drugs would have killed or seriously injured humans in phase 1 trials without the pre-human tests (which is about 900 people a year in the UK).
Preclinical results shape the human trial
But this is not the whole picture. The preclinical tests of all descriptions, including effects seen in animals, human cells, tissue samples and more, help to inform the design of human clinical trials in the first place. For instance, one or several of the tests might hint at potential issues with the liver, so extra measures can be taken to minimise that risk during the human trial.
All drugs have potential side effects, and their use is always a balance of risk vs potential benefit for the individual patient. All of this means that a large number of drugs proceed to human trials as ‘safe enough to try’ but with a question mark over whether their risks will be manageable or not.
An example of this management is paracetamol, which works better as a painkiller if taken regularly every 4-6 hours to allow it to build up in the tissues and bloodstream. However, we all know not to take a day’s dose all at once.
So, what of the 90%?
Drugs ‘fail’ at every stage of development and for several reasons. For every 100 possible drugs that even get to the animal testing stage, some 5,000 other compounds have already been eliminated. Drugs continue to be removed all the way through human testing too, in ever smaller numbers as we zero in on something that’s going to work.
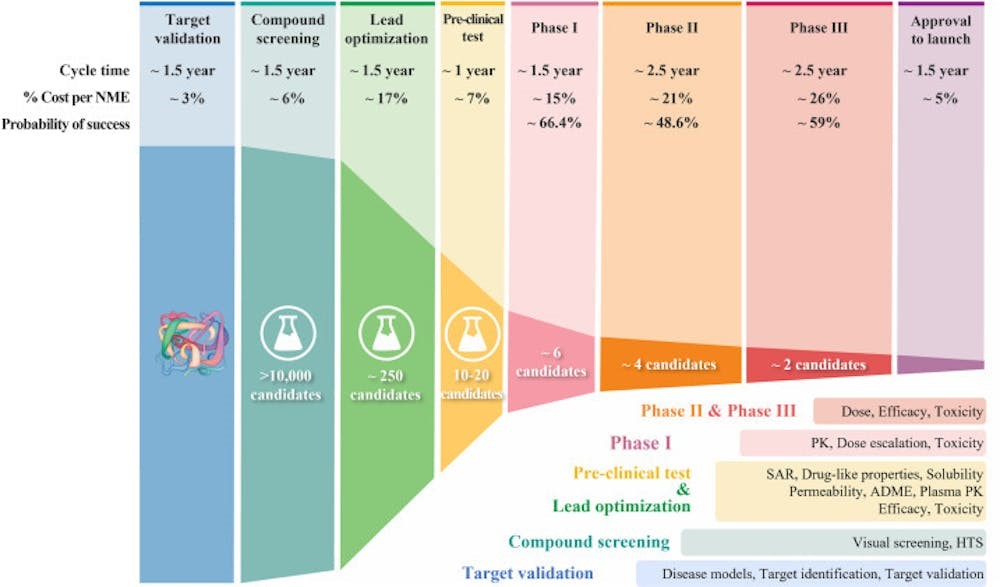
Percentages thus become less and less helpful for understanding what is happening. Having eliminated 5,000 candidates, for instance, we can be left with 10. If three of those 10 fails, then that’s 30%, which sounds massive, but it’s only 0.06% of the huge pile of 5,000 possible drugs we started with.
In the same way, the 90% statistic is easy to misunderstand.
As we’ve seen, 40% of possible drugs are removed as dangerous by the pre-human safety tests that are mainly in animals. The 90% that ‘fail’, then, is 90% of the 60% that pass preclinical trials. Also, by ‘failure’ it means to have failed for the purpose intended – many drugs can be repurposed even if they fail in their intended application.
What all this means is, for every 100 potential new drugs at the start of the process, 6 will become drugs in the pharmacy, 40 will be removed by preclinical tests and 54 will be removed for other reasons.
Exactly what those reasons are is the critical point.
Of those 54:
- C40-50% (26 drugs) will not be effective at the safe dose (something the animal test isn’t looking for);
- C25-30% (15 drugs) suspected or known toxicities cannot be managed;
- C10-15% (8 drugs) don’t absorb into the body or get to their target organ properly; and
- c10% (5 drugs) fail due to a lack of commercial need or misplaced strategic planning.
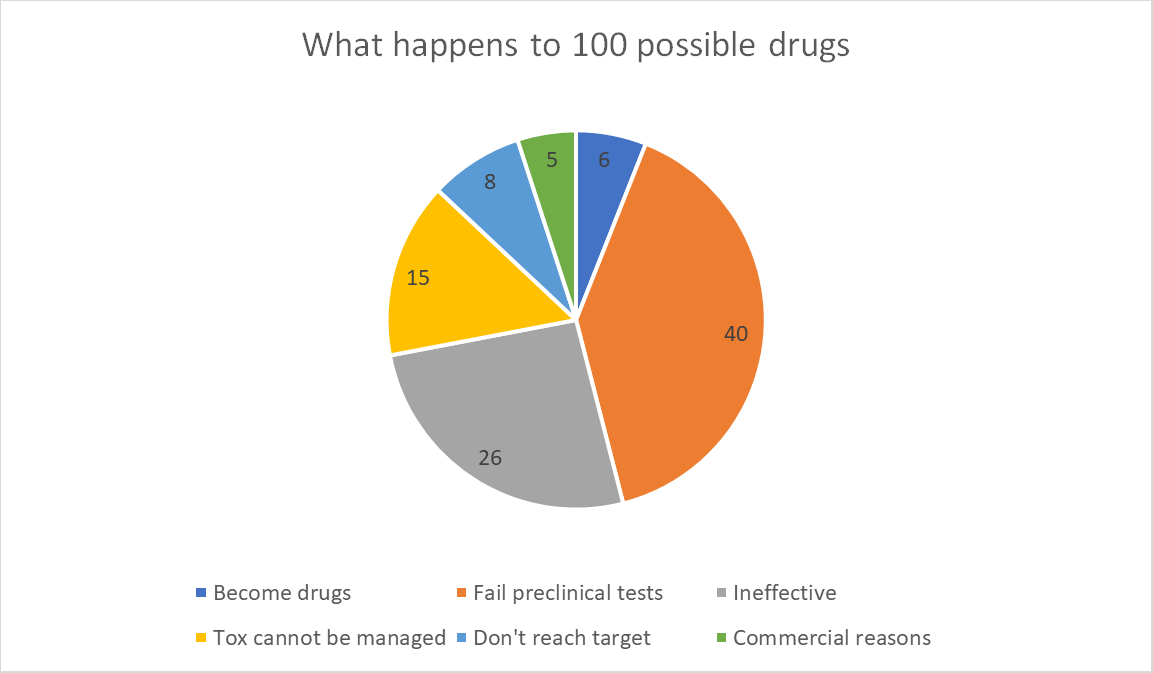
In this way, lots of drugs fail to make it to the chemists’ shelves, but this has very little to do with the efficacy of the animal model as a safety screen for stage 1 clinical trials. Animals do that job very well.
What is exciting about new approaches – whether they use animals or not - is that they may be able to chip away at the other reasons for failure (more on this later).
Where do NAMs fit in?
The term 'New Approach Methodologies' refers to the subset of non-animal technologies concerned with regulatory testing. Non-animal technologies have been in development and used in drug testing since the early 1970s, being applied alongside animal models to try to design better drugs, better clinical trials and spot potentially dangerous compounds. They have a more limited range of applications than a whole-body system, but can nevertheless be a quick, cheap and useful way of spotting red flags or pointing to a way forward. They are a standard part of the toolkit for drug testing, with their use accelerating exponentially in the past 20 years as technology improves. We have ever-better non-animal tests, which are still limited but can tell us enough in some cases to guide a decision on what compounds to try to turn into medicines.
Organs on chips
Some of these techniques are relatively new approaches like organ-on-a-chip technologies. First conceived in the late 1990s, the first successful chip was developed in 2010. These devices, roughly the size of an AA battery, are made from a flexible, translucent polymer. Inside are tiny tubes, each less than a millimetre in diameter, lined with living cells taken from a particular human or animal organ.
These can spot toxicities ranging from liver issues with new drugs to the effects on animals of industrial chemicals. They can be used early to avoid animal use and some emerging technologies could prevent up to 10% of drugs that would ultimately fail from entering animal trials in the first place. In a study completed late last year, for instance, liver chips identified compounds that were deemed safe enough to try by animal models, but would ultimately harm humans in wider testing, with 87% accuracy.
That doesn’t mean it can spot 87% of drug toxicities, but 87% of those that would have failed later and specifically for liver-related safety reasons. Given that 40% of compounds are removed prior to human testing, 30% later fail due to unmanageable toxicity and 30% of those do so due to effects on the liver, using this test routinely would help to reduce the number of drugs that later failed human trials for unmanageable toxicity by around a third, or 4-5 drugs for every 100 entering testing.
However, if also used early in the drug testing process they might also spot toxicities that would previously have needed an animal to detect, and this might be enough to halt testing. Liver toxicity is the reason for 14% of failures during preclinical tests so this would amount to a further 5 compounds per 100 that would not progress to the animal stage.
The UK authorises around 35 new drugs for use each year, yet for every drug approved another 9 fail, which would be around 315 trials, some 10% of which could be halted before hitting the animal or human stage, potentially preventing thousands of research animals from being born. This would undoubtedly save pharma companies money since human trials get more expensive the more they progress – from $ 25 million in Phase 1 to $ 54 million in Phase 3.
The UK’s national centre for Refining, Reducing or Replacing animal use has a project to replace ‘second species’ animals like dogs and primates with computer models that have passed its proof-of-principle stage and are well into development.
Even if this doesn’t work, it will tell us what we need to do to get it to work. As Jonas Salk, who used primates to create a polio vaccine, once said “There is no such thing as a failed experiment because learning what doesn't work is a necessary step to learning what does.”
New targets
Animal numbers will inevitably continue their steady march downward in terms of numbers, but it’s important to understand how all this fits together. Whilst it’s very easy to predict the future in general terms – clean energy, personalised medicine, healthier food – actually getting there is a bit of a slog.
The other big reason for drug failure beyond the liver, for instance, is Torsades de Pointes. French for “twisting of the points” it’s a dangerous heart arrhythmia that’s the reason for a very similar proportion of preclinical and clinical failures as liver problems. It makes heart chips the next big target for validation, with sincere hopes that they can be made to work as well as liver chips.
However, this is the low-hanging fruit on offer in terms of organ chips, with diminishing returns as the targets get harder, and the target systems get more complicated. A test for the heart or a kidney is one thing, a test for the Central Nervous System is quite another. In addition, heart arrhythmia and liver issues are the biggest single areas of failure for safety reasons, but the remaining 40% of reasons affect many other organs, each of which will need its own new animal or non-animal testing strategy.
Where next?
There is no one approach, then, that will create a revolution. We need new approaches, and we need new improvements to old approaches. My latest laptop, for instance, isn’t conceptually different from the first laptop I owned but it’s a lot faster and more effective. Improvements to clinical outcomes will come from organ chips, big data and AI, but also from higher standards of scientific rigour, new animal models, more powerful technology and the synergies that arise from using it altogether.
Happily, there are very few regulatory barriers to adopting new non-animal technologies, the ethical framework for using new animal models is well-understood and nobody is opposed to using non-animal methods over animals. In addition, whatever the costs of failure during clinical trials, the cost of preclinical R&D and discovery clocks in at $403 million, making it easily the most expensive single stage in the drug development process. Hence, the greatest savings in cost or animal use associated with improvements in technology may have nothing to do with the requirements of the regulator and can be implemented as soon as new technologies mature.
We do need to accelerate the validation of new animal and non-animal methods now that they’re emerging with rapidly increasing frequency. The OECD, the international association for sharing solutions to common problems, is the curator of scientific guidelines for the testing of chemicals. It makes the point that resources should be made available to test the reproducibility and reliability of new methods developed by single labs so that, if they work, they can be applied more widely, and more quickly. Inherent to their thinking is a bias against animal use.
We also need to make sure that politicians aren’t distracted by ideological sideshows or lured towards counterproductive policy directions. There are concrete measures that governments, or prospective governments, could be proposing but politicians of all stripes need to understand where to apply funding and focus to have the greatest impact.
Last edited: 9 September 2025 11:35


